Project 6: Reinforcement Gaming Agent
Introduction
Background
After working with Q-Tables I am now looking into other RL methods focusing in DQN. DQN leverages deep learning to approximate Q-values in high-dimensional state spaces, making it a powerful alternative when traditional Q-tables become impractical. The primary goal of this project is to design a simple, fast-paced game with an easily measurable scoring system ideal for evaluating the performance of the DQN agent.
A Deep Q-Network combines the traditional Q-learning algorithm with deep neural networks. In this setup, the neural network processes raw input data (for example, visual frames from the game) and outputs a set of Q-values corresponding to the available actions. The agent employs an epsilon-greedy strategy to balance exploration (trying new actions) and exploitation (leveraging learned strategies). Additionally, by using experience replay—where past experiences are stored and sampled randomly—the learning process is made more robust and less prone to instability. Periodically synchronizing with a target network further ensures that the Q-value approximations remain accurate over time. This approach empowers the DQN to learn effective policies even in environments with a vast or continuous state space.
Deliverables (High-Level Scope)
- Game: Developed a lightweight game that maintains low complexity and ensures a rapid pace. This design choice facilitates quick iterations and reliable point measurements to assess the agent’s performance.
- Environment: Built a robust game environment that acts as the interface for the DQN agent. The environment manages game state transitions, reward calculations, and enforces rules for agent interactions, all detailed in the project files.
- DQN Training: Implemented the core learning component that trains the DQN agent. This module incorporates key techniques such as experience replay and target network updates to stabilize and enhance the learning process.
Out of Scope
- The project is designed as a proof-of-concept (PoC) to demonstrate the viability of DQN in a controlled setting. Advanced optimizations or fine-tuning for maximum performance are not the primary focus.
- No user interface will be built. All interactions with the agent and environment are conducted directly via the console. A dedicated UI for user interaction is intentionally omitted to keep the focus on the core RL techniques.
High-Level Design
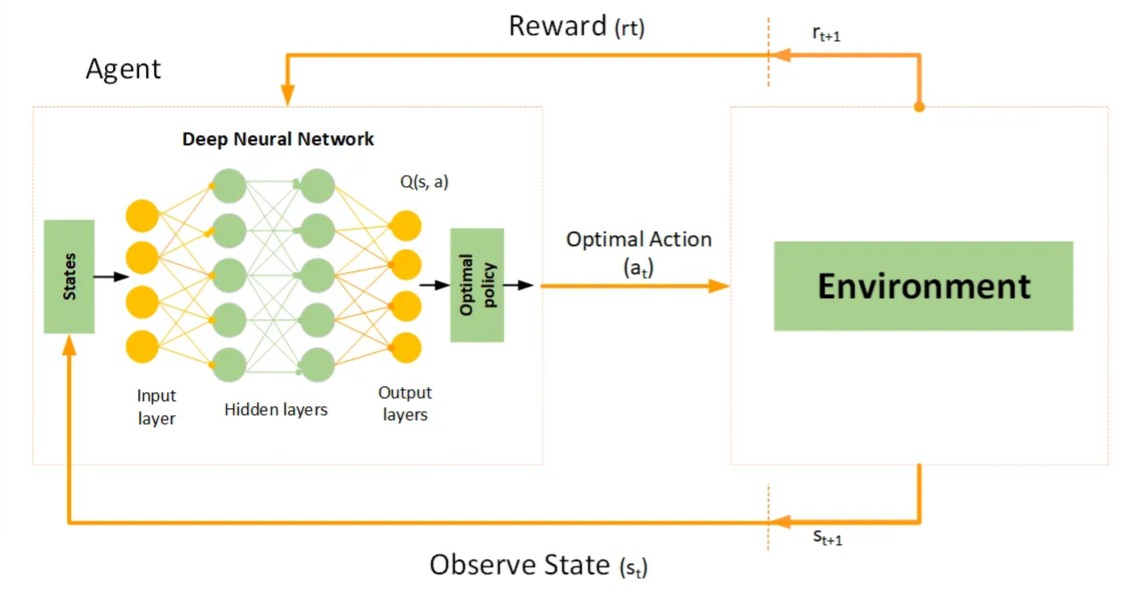
The image illustrates how a Deep Q-Network (DQN) operates. The agent receives a state from the environment, which is processed by a deep neural network. The network then outputs Q-values for possible actions, and the optimal action is selected. This action is executed in the game environment, leading to a reward based on its effectiveness. The agent uses this feedback to adjust its behavior over time, improving its decision-making through reinforcement learning.